General Trees & Binary Trees
CSC Data Structures and Algorithms
Tree Terminology

Visual representation of various tree terms
Full vs. Complete

Examples of full vs complete
Note
Tree a shows a perfect binary tree. It is not necessarily true that a tree that is full is also complete and vice versa. Tree b is complete but not full. Node L only has 1 child which violates the “exactly 2 child nodes” of a full tree.
Number of Nodes and Height
- There is a relationship between the number of nodes and the tree height of a perfect binary tree
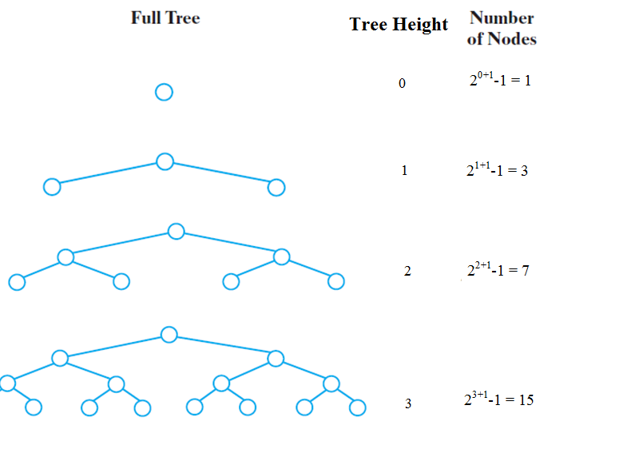
\[ n = 2^{h + 1} - 1 \]
- \(n\) is the number of nodes
- \(h\) is the height
- Number of leaf nodes (\(l\)) can be calculated
\[ l = 2^h \]
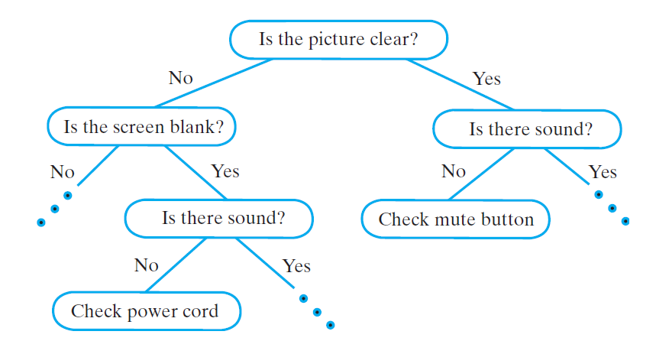
Example of Decision Trees
- Expert systems use decision trees to provide solutions based on inputs
- Helps users solve problems
- Parent node asks a question
- Child nodes provide conclusion or further questions
Example of Expression Trees
- Trees are used widely in compilers to represent the structure of a program

Examples of expression trees
Example of Game Trees
- The goal of game trees is used in game playing AI as an attempt to find the best move to make
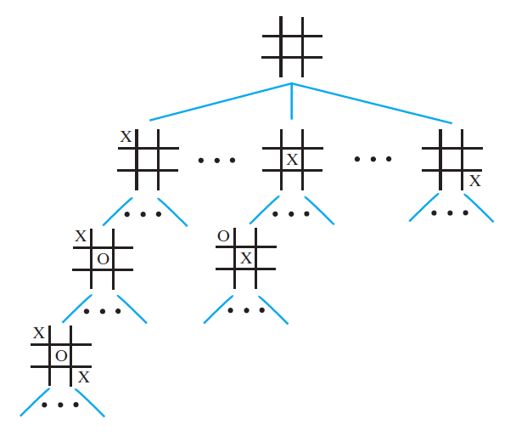
Game Tree for Tic Tac Toe
Pre-Order Traversal
- The order of processing nodes
- Parent then left subtree then right subtree
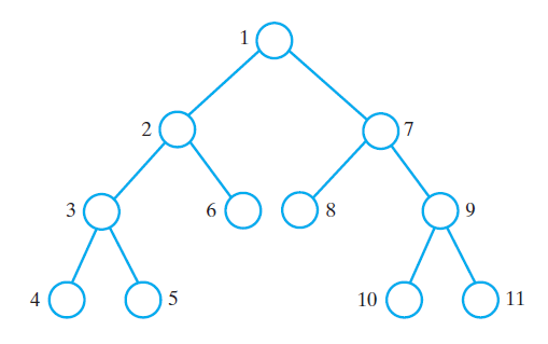
The order in which each node is processed in pre-order
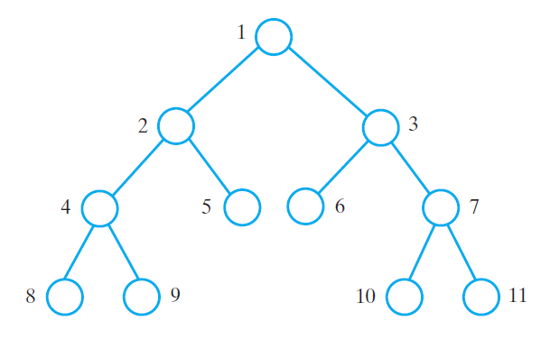
In-Order Traversal
- The order of processing nodes
- Left subtree then parent then right subtree

The order in which each node is processed in in-order
Post-Order Traversal
- The order of processing nodes
- Left subtree then right subtree then parent
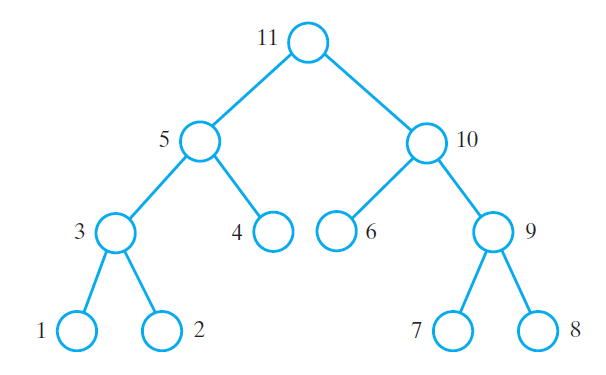
The order in which each node is processed in post-order
Example Traversal of Expression Tree
- Suppose the compiler built the following tree for the expression \(2 * (4 - (5 + 3))\)

- Pre-Order Traversal
- \(* \ 2 - 4 + 5 \ 3\)
- In-Order Traversal
- \(2 * 4 - 5 + 3\)
- Post-Order Traversal
- \(2 \ 4 \ 5 \ 3 + - *\)
Breadth-First Traversal
- Breadth-First traversal is the opposite of depth-first
- It visits all nodes in one level before going to a deeper level
- Top-to-bottom, left-to-right
- It is also called level-order traversal
Example of Adding

Example of adding to a Binary Tree
Alternative Remove Example 1


Alternative Remove Example 2

- C does not have any left children so no shifting is done
- We want to remove C and since it is the right child we replace the parent’s right child with C’s right child
Finished
postorder(root)
